3.2.1 Liht- ja struktuurandmetüübid. Andmestruktuurid - kirjed, massiivid, ahelad
Muutujad
Programmeerimise käigus on reeglina vaja hoida meeles mingit hulka andmeid (vahetulemused, toimunud sündmused, sisendväärtused, väljundväärtused jne). Neid väärtused tuleb hoida mälus. Selleks defineeritakse koht mälus, mida kasutatakse andmete hoidmiseks ning seda defineeritud kohta nimetatakse muutujaks. Kuna andmed, mida hoitakse, võivad olla väga erinevad, siis öeldakse ka muutuja defineerimisel, mis tüüpi andmeid selles muutujas hoidma hakatakse (muutujatüüp).
Lihttüübid
Lihttüüpi muutujas on märksõna all peidus üks väärtus (enamasti arvuna loetav) ning ta on sealt otse kättesaadav. Tuntumad lihttüübid on: märgiga täisarv, märgita täisarv, reaalarv (komakohaga), tähemärk, tõeväärtus. Keeleti võivad nad mõnevõrra erineda.
Struktuurtüübid
Struktuurtüüpides koondatakse ühe märksõna alla mitu kokkukuuluvat väärtust nagu näiteks punkti koordinaadid või inimese ees- ja perekonnanimi. Selliselt on andmekogumit kergem korraga edasi anda. Samas andmeid kasutada või muuta tuleb enamasti ikka struktuuri seest ükshaaval.
Massiivid
Massiiv on ühetüübiliste muutujate kogum, millistel on üks nimi ja mis on üksteisest eristatavad indeksi poolest. Massiivid lihtsustavad oluliselt ühetüübiliste andmete töötlemist. Lihtsustamine tuleneb sellest, et programmi täitmise käigus on võimalik indeksit lihtsalt muuta ja seega on lihtsam pöörduda vajaliku muutuja poole. Massiivist järjekorranumbri järgi väärtuse küsimine on arvuti jaoks suhteliselt kiire operatsioon.
Massiivid võivad olla ühemõõtmelised (jada, rida), kahemõõtmelised (tabel, maatriks), kolmemõõtmelised (kuup), jne.
Näide (C#, Java)
int[] mass = new int[10]; //luuakse massiiv kümne täisarvu hoidmiseks.
mass[0]=1; //kohale 0 kirjutatakse väärtus 1
Lisalugemist: http://enos.itcollege.ee/~jpoial/java/i200loeng4.html
Kirjed
Hoidmaks erinevate tüüpi andmeid, mis moodustavad koos mingi seostatud kogumi kasutatakse kirjeid. Näiteks moodustub kirje inimene järgmistest andmetest: eesnimi (tekst), perenimi (tekst), sugu (tõeväärtus, 0- naine, 1 -mees), kaal (reaalarv). Sellised andmed moodustavad ühtse terviku ühe inimese kirjeldamiseks, kuid eraldiseisvana on väga erinevat tüüpi.
Näide (C#)
struct inimene {
public string eesnimi;
public string perenimi;
public bool sex;
public float weight;
}
Sellise kirjega saame luua uue muutuja kasutaja ja anda kasutajale, eesnime, perenime, soo ja kaalu:
inimene kasutaja;
kasutaja.eesnimi = "Jaan";
kasutaja.perenimi = "Mets";
kasutaja.sex = 1;
kasutaja.weight = 80.0;
Ahelloendid ja puud
Kaasajal kasutatakse tihti andmete hoidmiseks loendeid (list). Kui iga listi liige viitab järgmisele, siis on tegemist ahelloendiga, ahelloendi lõppu märgib tühiliige (null). Ahelloend, kus iga liige viitab järgmisele nimetatakse ühesuunaliseks loendiks, ahelloend, kus iga liige viitab eelmisele ja järgmisele nimetatakse kahesuunaliseks loendiks. Ahelloend, kus puudub esimene ja viimane liige ning iga liige viitab järgmisele nimetatakse ringloendiks. Ahelloendi pikkus on loendi liikmete arv. Loendi esimene liige on pea (head) ja ühejäänud liikmed saba (tail).
Pinu (stack) on ahelloend, kus viimasena lisatud liige loetakse välja esimesena ( LIFO - Last In First Out).
Järjekord (queue) on ahelloend, kus esimesena lisatud liige loetakse välja esimesena ( FIFO - First In First Out)
Lisalugemist: http://www.cs.tlu.ee/~inga/alg_andm/linked_list_C_2011.pdf
Puu on andmestruktuur, kus andmed on paigutatud puukujuliselt, koosneb tippudest (nodes) ja kaartest (edges), mis ühendab tippe (viited). Tipud, mis on ühendatud kaarega üleval asuva tipu külge on lapsed (childs) ja üleval asuv tipp on sellisel juhul vanem (parent). Kõige ülemine tipp on juur (root). Tippu, millel ei ole lapsi, nimetatakse leheks (leaf).
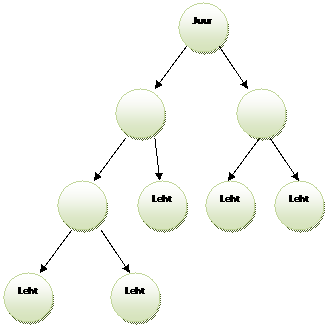
Liikudes tipust vanemasse, sealt vanemasse jne jõuame Juurde. Esivanemad on kõik tipud mis jäävad vaadeldava tipu ja juure vahepeale. Puu kõrgus (tree height) on pikim tee lehest juureni.
Järjestatud puu korral on defineeritud juur ja otse juurega ühendatud tipud on esimese taseme tipud (first level nodes, juure lapsed), esimese taseme tippudega otse ühendatud tipud on teise taseme tipud (esimese taseme tippude lapsed) jne ning laste järjekord vasakut paremale on oluline.
Lisalugemist: http://www.cs.tlu.ee/~inga/alg_andm/tree_gen_2011.pdf
Kahendpuu on selline puu, kus igal vanemal võib olla mitteühtegi, üks või kaks last ja laste järjekord on oluline.
Kahend-otsingupuu (binary search tree) on kahendpuu, mis on järjestatud. Tipust vasakul on alati väiksem suurus ja tipust paremal suurem suurus.
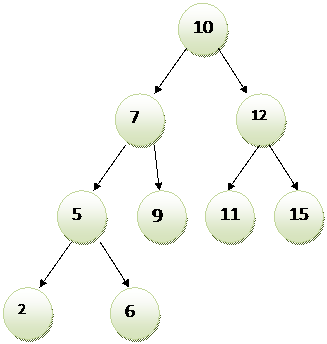
Sellisest puust otsides võrreldakse otsitavat väärtust juurega, kui otsitav väärtus võrdub juure väärtusega, siis väärtus eksisteerib, kui aga juure väärtus ei võrdu otsitavaga, siis võrreldakse väärtust edasi, vastavalt kas vasaku või parema tippude hulgast kuni jõutakse leheni. Kui otsitav väärtus on võrdne mõne tipu väärtusega, siis on otsitav element olemas, kui aga ei leidu võrdset väärtust, siis otsitavat elementi ei ole. Selline otsimise viis on kordi kiirem kui oleks näiteks ahelloendi või massiivi läbivaatamine.
B-puu (B tree) on otsingupuu, milles iga tipu tütarde arv asub vahemikus (t-1) kuni (2t-1) , kus t on suvaline konstant
B*-puu on B-puu, kus tippude täituvus hoitakse 2/3 juures, täites kaks tütartippu võtmete ümberjaotamise teel ja tükeldades nad seejärel kolmeks tipuks.
B-puu võimaldab nõnda hoida puu sügavust kahendpuust väiksemana. Täituvust piirates on võimalik vahetasemetel hoida kindlaksmääratud suurusega mälumahtu ning samas pääseb sinna sobivasse kohta kohe andmeid lisama.
Lisalugemist: http://enos.itcollege.ee/~jpoial/algoritmid/puustruktuurid.html